Heroku custom platform repo for V8Js
Yesterday @dzuelke poked me to migrate the old PHP buildpack adjusted for V8Js to the new custom platform repo infrastructure. The advantage is that the custom platform repo only contains the v8js extension packages now, the rest (i.e. Apache and PHP itself) are pulled from the lang-php bucket, aka normal php buildpack.
As I already had that on my TODO list, I just immediately did that :-)
… so here’s the new heroku-v8js Github repository that has all the build formulas. Besides that there now is a S3 bucket heroku-v8js that stores the pre-compiled V8Js extensions for PHP 5.5, 5.6 and 7.0. packages.json file here.
To use with Heroku, just run
$ heroku config:set HEROKU_PHP_PLATFORM_REPOSITORIES="https://heroku-v8js.s3.amazonaws.com/dist-cedar-14-stable/packages.json"
with Dokku:
$ dokku config:set YOUR_APPNAME HEROKU_PHP_PLATFORM_REPOSITORIES="https://heroku-v8js.s3.amazonaws.com/dist-cedar-14-stable/packages.json"
replacing Huginn with λ
I used to self-host the Ruby application Huginn which is some kind of IFTTT on steroids. That is it allows to configure so-called agents that perform certain tasks online, automatically. One of those tasks was to regularly scrape the Firefox website for the latest firefox version number (which happens to be a data-attribute on the html element by the way), take only the major version number, compare it to the most recent known value (aka last crawl cycle) and send an email notification if it changes. I wanted to have that notification so I could test, update & release Geierlein.
The thing is that that worked really well (I had it around for almost a year now), … nevertheless I decided to cut down (many) self-hosted projects (saving time on hosting, constantly updating, etc. to have more time for honing my software development skills). But I still needed those notifications so I had to find an alternative … and I found it in AWS Lambda.
(actually I’ve been interested in Lambda since they had it in private beta, I even applied for the beta program, … but never really used it as I had no idea what to do with it back then)
So my all AWS services approach involves
- a CloudWatch scheduler event that triggers AWS Lambda
- AWS Lambda doing the web scraping & flow control
- S3 to persist the last known major version number
- SES (simple e-mail services) to send the e-mail notification
I’ve used S3 and configured stuff with IAM before, SES is really straight forward, so actually only Lambda was new to me. Then the learning curve is okayish, as the AWS documentation guides into the right direction and Google + StackOverflow helps for the rest. If you’ve never used AWS services before, then the learning curve might be a bit steeper (mainly because of IAM) …
All in all I got it working within two hours or maybe three … and it just works now :)
… without nothing for me to host anymore
… and actually everything for free (as Lambda & SES stay within free usage quota and the single S3 object’s cost is negligible)
In case you want to follow along, here’s my …
step by step guide
under IAM service …
- create AWS user with API keys to do local development (using AWS root account is undesirable)
- grant that user the necessary permissions
- managed policy
AWSLambdaFullAccess(that includes full access to logs & S3) - yet it doesn’t include the right to send e-mails via SES, therefore create a user policy like
- managed policy
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1459031930000",
"Effect": "Allow",
"Action": [
"ses:SendEmail"
],
"Resource": [
"*"
]
}
]
}
under S3 service …
- create a new Bucket to be used with Lambda, I picked lambdabrain (so pick something else)
again under IAM service …
- create an AWS role, to be used by our lambda function later on
- choose AWS Lambda from AWS Service Roles in Step 2 of the assistant, then attach
AWSLambdaBasicExecutionRolepolicy - do not attach the
AWSLambdaExecutemanaged policy as it includes read/write access to all object of all your S3 buckets - last not least add a custom Role Policy to grant rights on the newly created S3 Bucket +
ses:SendEmailwith
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::lambdabrain"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::lambdabrain/*"
]
},
{
"Effect": "Allow",
"Action": [
"ses:SendEmail"
],
"Resource": [
"*"
]
}
]
}
… turns out the s3:ListBucket is actually needed to initially create the persistance object.
under AWS SES
- validate your mail domain (so you can send mails to yourself)
- if you would like to send mails to other domains you also need to request a limit increase also
After setting up AWS CLI finally it’s time to (locally) create a Node.js application (the Lambda function to be).
- create a new folder
- … and an initial
package.jsonfile like this:
{
"name": "firefox-version-notifier",
"version": "0.0.1",
"description": "firefox version checker & notifier",
"main": "index.js",
"dependencies": {
"promise": "^7.1.1",
"scrape": "^0.2.3"
},
"devDependencies": {
"node-lambda": "^0.7.1",
"aws-sdk": "^2.2.47"
},
"author": "Stefan Siegl <stesie@brokenpipe.de>",
"license": "MIT"
}
I used promises throughout my code, and scrape to do the web scraping.
-
aws-sdkis actually needed in production as well, still I declared it underdevDependenciesas it is available globally on AWS Lambda and hence need not be included in the ZIP archive upload later on. -
node-lambdais a neat tool to assist development for AWS Lambda - run
npm installand./node_modules/.bin/node-lambda setup - configure node-lambda through the newly created
.envfile as needed-
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEYof the IAM user from above -
AWS_ROLE_ARNis the full role ARN (from above) -
AWS_HANDLER=index.handler(indexbecause of theindex.jsfile name,handlerwill be the exported name in there)
-
Here’s my straight-forward code, … definitely deserves some more love, yet it’s just a better shell script …
Adapt the name of the S3 bucket and the e-mail addresses (sender and receiver) of course.
var Promise = require('promise');
var AWS = require('aws-sdk');
var scrape = Promise.denodeify(require('scrape').request);
var brain = new AWS.S3({ params: { Bucket: 'lambdabrain' }});
var ses = new AWS.SES();
function getCurrentFirefoxVersion() {
return scrape('https://www.mozilla.org/en-US/firefox/new/')
.then(function($) {
var currentFirefoxVersion = $('html')[0].attribs['data-latest-firefox'].split(/\./)[0];
console.log('current firefox version: ', currentFirefoxVersion);
return currentFirefoxVersion;
});
}
function getBrainValue(key) {
return new Promise(function(resolve, reject) {
brain.getObject({ Key: key })
.on('success', function(response) {
resolve(response.data.Body.toString());
})
.on('error', function(error, response) {
if(response.error.code === 'NoSuchKey') {
resolve(undefined);
} else {
reject(error);
}
})
.send();
});
}
function setBrainValue(key, value) {
return new Promise(function(resolve, reject) {
brain.putObject({ Key: key, Body: value })
.on('success', function(response) {
resolve(response.requestId);
})
.on('error', function(error) {
reject(error);
})
.send();
});
}
function sendNotification(subject, message) {
return new Promise(function(resolve, reject) {
ses.sendEmail({
Source: 'stesie@brokenpipe.de',
Destination: { ToAddresses: [ 'stesie@brokenpipe.de' ] },
Message: {
Subject: { Data: subject },
Body: {
Text: { Data: message }
}
}
})
.on('success', function(response) {
resolve(response);
})
.on('error', function(error, response) {
console.log(error, response);
reject(error);
})
.send();
});
}
exports.handler = function(event, context) {
Promise.all([
getCurrentFirefoxVersion(),
getBrainValue('last-notified-firefox')
])
.then(function(results) {
if(results[0] === results[1]) {
console.log('Firefox versions remain unchanged');
} else {
return sendNotification('New Firefox version!', 'Version: ' + results[0])
.then(function() {
return setBrainValue('last-notified-firefox', results[0]);
});
}
})
.then(function(results) {
context.succeed("finished");
})
.catch(function(error) {
context.fail(error);
});
};
-
exports.handlerfunction initially creates an all-promise that (in parallel)- scrapes the Firefox website
- fetches the S3 object
- then compares the two and (if different) …
- creates another promise to send a notification
- … (if successful) then updates the S3 object
- and finally marks the lambda function as successful (via
context.succeed)
I really like how the promises allow to easily parallelize stuff as well as make things depend on another (S3:PutObject on SES:SendMail)
Run ./node_modules/.bin/node-lambda run to test the script locally. If it works run ./node_modules/.bin/node-lambda deploy to upload.
Back in the AWS console, now under “Lambda”
- you should see the new function, click it and hit “Test” to try it on AWS.
- if it does, choose “Publish new version” from the “Actions”.
- under “Event sources” add a new event source, choose “CloudWatch Events - Schedule” and choose an interval (I picked daily)
V8Js: improved fluent setter performance
After fixing V8Js’ behaviour of not retaining the object identity of passed back V8Object
instances (i.e. always re-wrapping them, instead of re-using the already existing object)
I tried how V8Js handles fluent setters (those that return $this at the end).
Unfortunately they weren’t handled well, that is V8Js always wrapped the same object again and again (in both directions). Functionality-wise that doesn’t make a big difference since the underlying object is the same, hence further setters can still be called.
But still the wrapping code takes some time – with simple “just store that” setters it is approximately half of the time. Here is a performance comparison of calling 200000 minimalist fluent setters one after another:
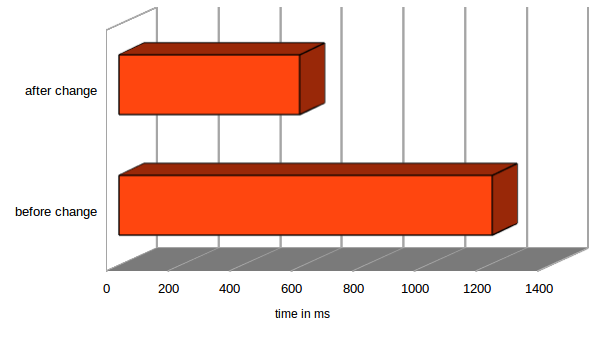
Besides the performance gain it also keeps object identity intact, however I assume noone ever stores the result of such a setter to a variable and compares it against another object. So that isn’t a big deal by itself.
V8PromiseFactory
V8 has support for ES6 Promises and they make a clean JS-side API. So why not create promises from PHP, (later on) being resolved by PHP?
V8Js doesn’t allow direct creation of JS objects from PHP-code, a little JS-side helper needs to be used. One possibility is this:
class V8PromiseFactory
{
private $v8;
public function __construct(V8Js $v8)
{
$this->v8 = $v8;
}
public function __invoke($executor)
{
$trampoline = $this->v8->executeString(
'(function(executor) { return new Promise(executor); })');
return $trampoline($executor);
}
}
… it can be used to construct an API method that returns a Promise like this:
$v8 = new V8Js();
$promiseFactory = new V8PromiseFactory($v8);
$v8->theApiCall = function() use ($promiseFactory) {
return $promiseFactory(function($resolve, $reject) {
// do something (maybe async) here, finally call $resolve or $reject
$resolve(42);
});
};
$v8->executeString("
const p = PHP.theApiCall();
p.then(function(result) {
var_dump(result);
});
");
this code
- initializes V8, V8Js and the
V8PromiseFactoryfirst - then attaches an API call named
theApiCall, that uses$promiseFactoryand passes it an executor that immediately resolves to the integer 42. - then executes some JavaScript code that uses the
theApiCallfunction and attaches athenfunction that simply echos the value (42)
V8PromiseFactory::__invoke should cache $trampoline if it is used to create a lot of promises.
This code requires V8Js with pull request #219 applied to function properly.
thoughts on phpspec
As I’ve recently been poked whether I had used phpspec and I had to negate, today I finally gave it a try (doing the Bowling Kata) …
phpspec has some class and method templating built into it. If for example a test fails due to a missing function, it asks whether it should create one (that does nothing at all). This is nice but IMHO breaks the workflow a bit as you have to move the cursor to the terminal window and answer the question. You don’t just Shift+F10, see “red” in the panel and then hit Alt+Enter in PhpStorm and choose to create the method (which is my way of working with phpunit).
I like the well readable test code that can be written with it like
$this->getScore()->shouldReturn(150)
… yet that code shows also what I hate about it. Since $this actually is the test-class, having to call the message to test on it feels strange (or even wrong) and also phpstorm has no support for that … so no auto-completion here.
Calling methods of the SUT directly on $this gets even more messy once you add test helper methods like
function it_grants_spare_bonus()
{
$this->rollSpare();
$this->roll(5);
$this->rollMany(17, 0);
$this->getScore()->shouldBe(20);
}
… here only roll is a method of the SUT, rollSpare and rollMany are just helper methods.
After all I’m still torn, I like the readability, but the rest still feels strange and I miss native support in PhpStorm.
phpspec screencast
After @sD_Tobi recently poked me whether I knew phpspec, … and initially I had no idea except for having heard of it … I found this excellent screencast on laracasts.com to get a first impression. It’s just 17 minutes and he’s really enthusiastic about it :-)
happy & lucky numbers
The other day I paired with the guys from @solutiondrive and @niklas_heer, we had a fun evening learing about happy numbers, shared PhpStorm knowledge, tried Codeception etc. Actually we didn’t even finish the “Happy Numbers” Kata, since we only wrote the classifying routine, not the loop generating the output.
On my way home I kept googling and also found out about Lucky Numbers. Lucky numbers are natural numbers, recursively filtered by a sieve that eliminates numbers based on their position (where the second number tells the elimination offsets).
So I immediately came up with another Kata: generating those numbers.
My constraint: no upper limit, i.e. use PHP’s Generator instead
… so I came up with the idea to implement the sieve itself as a Generator, that reads from an injected Generator, filters as needed and yields the result. The first “sieve generator” is fed from another generator that simply yields all natural numbers. The second one is fed from the first one and so on. The generator into generator injection is handled by yet another generator … turn’s out: it works, but doesn’t look so nice.
The outer generator cannot simply inject generators endlessly (since they are actually instanciated), so injection has to be deferred - that however dilutes the self-contained sieve generator :-(
Anyways it was a good exercise on PHP’s generators. I think I’ll give it another try soon, again with generators yet another approach.
funny Math.random behaviour
Playing around with V8’s custom startup snapshots
I noticed some funny behaviour regarding Math.random.
It is clear that if you call Math.random() within the custom startup code the generated random numbers are
baked into the snapshot and then not so random anymore. If you call Math.random() at runtime, without custom
startup code, it just behaves as expected: it generates random numbers. However if you have custom startup code,
calling Math.random() early on startup, it correctly generates random numbers during startup but
it breaks runtime random number generation causing weird error messages like
TypeError: Cannot read property '4' of undefined
@virgofx raised this issue at the V8 issue tracker.
For the moment I came up with using random numbers from PHP’s Mersenne Twister
$this->v8 = new V8Js('PHP', [], [], true, $blob);
$this->v8->__random = function() { return mt_rand() / mt_getrandmax(); };
$this->v8->executeString('Math.random = PHP.__random; ');